What is Predictive maintenance?
Predictive maintenance is an approach to maintaining operational industrial assets such as jet engineers, wind turbines, and oil pumps using predictive models. These predictive models use sensor data and other information to detect anonalies, monitor the health of components and most importantly estimate the remaining useful life (RUL). With predictive maintenance, you can schedule timely maintenance; not too early and definitely not too late.
Why it Matters?
To understand what makes predictive maintenance such an attractive proposition, it is important to understand the shortcomings of the alternatives – reactive maintenance and preventive maintenance.
Reactive Maintenance and Preventive Maintenance
Most operators therefore perform preventive maintenance, scheduling maintenance at regular intervals without considering the actual condition of the machine. While this approach mitigates the risk of failure compared to reactive maintenance, it results in higher maintenance costs, increased downtime, and an associated increase in inventory and spare assets. It also does not prevent unexpected failures as the condition of the asset is only measured periodically, rather than monitored and analyzed continuously in real-time.
predictive maintenance
Predictive maintenance resolves the issues faced by the other two approaches by monitoring the condition of the asset continuously and providing constant estimates of when it will fail or require maintenance. This minimizes unexpected downtime and reduces operational costs by ensuring maintenance is only performed when required. In addition, developing a successful predictive maintenance solution enables manufacturers to generate a new revenue stream by providing maintenance as a service to their customers.
how predictive maintenance works
At the heart of a predictive maintenance solution is an algorithm that analyzes sensor data from an asset and uses this data to detect anomalies, diagnose equipment problems, or predict the remaining useful life (RUL) of the asset.
Developing this algorithm requires engineers to gather the appropriate data, and then use tools such as MATLAB® to preprocess it and extract features from it, then use these features as input to a machine learning or deep learning model that makes a prediction. This algorithm is then deployed at scale in IT/OT systems to which data from multiple assets and equipment is being streamed. If this final step is not completed successfully, the benefits of a predictive maintenance solution will not be realized.
Failure data
Collecting data is the first step in developing any predictive maintenance algorithm. Machine learning and deep learningmodels are only accurate if they have robust training data that represents the types of failures you want to predict. It is therefore important to collect data that represents the asset under both healthy and failing conditions.
However, data corresponding to equipment failure events is often hard to access – after all, the goal of any maintenance program is to prevent failure! This makes it hard for engineers and data scientists to get the right kind of data to start building their algorithm.
One solution to this problem is to use virtual models, such as those built in Simulink®, to represent the asset dynamics and simulate faults. For example, an engineer can build a model of an oil pump and simulate failures due to a leaky valve and a blocked pipe. Then it’s possible to collect failure data in a cost-effective way that does not impact the performance of the actual oil pump. In fact, generating failure data for predictive maintenance algorithm development is one of the benefits of investing in digital twins.
Feature Extraction
Once you have the necessary data, the next step is to preprocess it and reduce it to a set of features that can be used as “condition indicators.” These condition indicators capture the relevant information pertaining to asset health. They are typically extracted using a combination of statistical, signal processing, and model-based techniques, implemented in analysis and design tools such as MATLAB and Simulink. It is also the stage of algorithm development where the engineering team’s input is key as they have unique insight into how their asset performs.
Identifying the right condition indicators is key to the success of a predictive maintenance algorithm. It enables engineers to monitor a significantly smaller dataset to determine why their asset is performing the way it is. For example, commercial airplanes generate close to a terabyte of data per flight. Analyzing such vast amounts of data can be really difficult, which is why feature extraction is becoming increasingly important. An added benefit is that it helps reduce data storage and data transmission costs.
Predictive models
Machine learning and deep learning models distinguish predictive maintenance solutions from a traditional condition-based monitoring approach. These models use condition indicators as inputs to detect the root cause of an anomaly or predict when an asset might fail. Condition-based monitoring can provide real-time updates, but doesn’t predict the future condition of the asset.
If there are condition indicator values available for different failure modes, engineers and data scientists can use supervised learning methods to train predictive models that can differentiate between these failure modes. These models can then be connected to assets in the field where they can help isolate the root cause of an issue affecting the performance of the asset.
Unsupervised learning methods are better suited to applications like anomaly detection where the goal is to classify incoming condition indicator values from equipment as either “normal performance” or “abnormal performance”. As unsupervised learning methods do not require labeled training data corresponding to different failure modes, they tend to be very popular for engineers trying to develop predictive maintenance algorithms for the first time.
A separate class of probability and time-series based methods can be used to calculate the remaining useful life (RUL) of a machine. These models accept the current value of a condition indicator and estimate within a defined confidence interval when the equipment will fail. In fact, these RUL models are a form of digital twins as they model the gradual degradation of a particular operating asset. Armed with information regarding the range of time in which their asset may fail, engineers can schedule maintenance at the right time, order spare parts, or limit the operation of the asset to extend its life.
Deployment and operationalisation
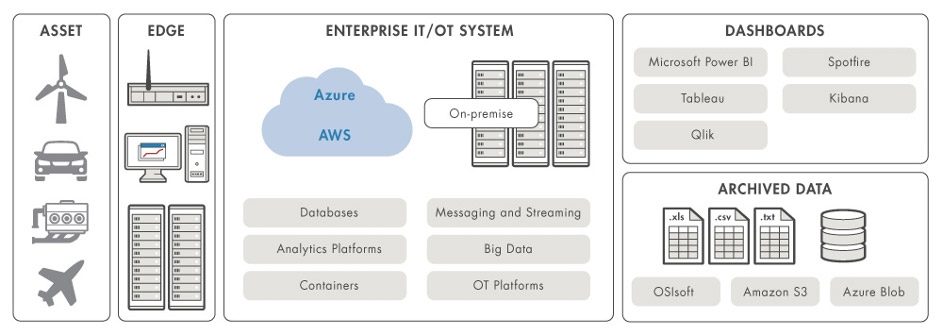
The production environment in which this algorithm runs must securely manage data generated by several operating assets and scale computing resources as needed to ensure that the algorithms are able to run as effectively as possible across edge or IT/OT systems. The production environment must also integrate with other IT systems for managing inventory, raising service tickets, and presenting dashboards with the results of the algorithm to the operations team responsible for the assets.
It is important to note that in these production environments, predictive maintenance algorithms are not just running on the cloud or on on-premises servers. Parts of the algorithm, especially those related to data preprocessing and feature extraction, can be evaluated on edge devices like industrial controllers that sit right next to the operating asset and are able to process the high-velocity data it generates. This helps reduce data storage and transmission costs.
